
In this blog post I would like to express my personal experiences about Captiva from OpenText. It happens very often that neither users nor IT specialists know exactly what is behind this “software tool”.
I have also heard the sentence “It’s just scanning” more often and exactly for this reason, it is time to illuminate the mystery Captiva Capture. In simple words I try in this article to tell something about the software itself and about the daily tasks and problems. Maybe it is then comprehensible, why I find this area with the activities connected with it insanely exciting and that thereby more hides itself, than only scanning.
What is Captiva Capture?
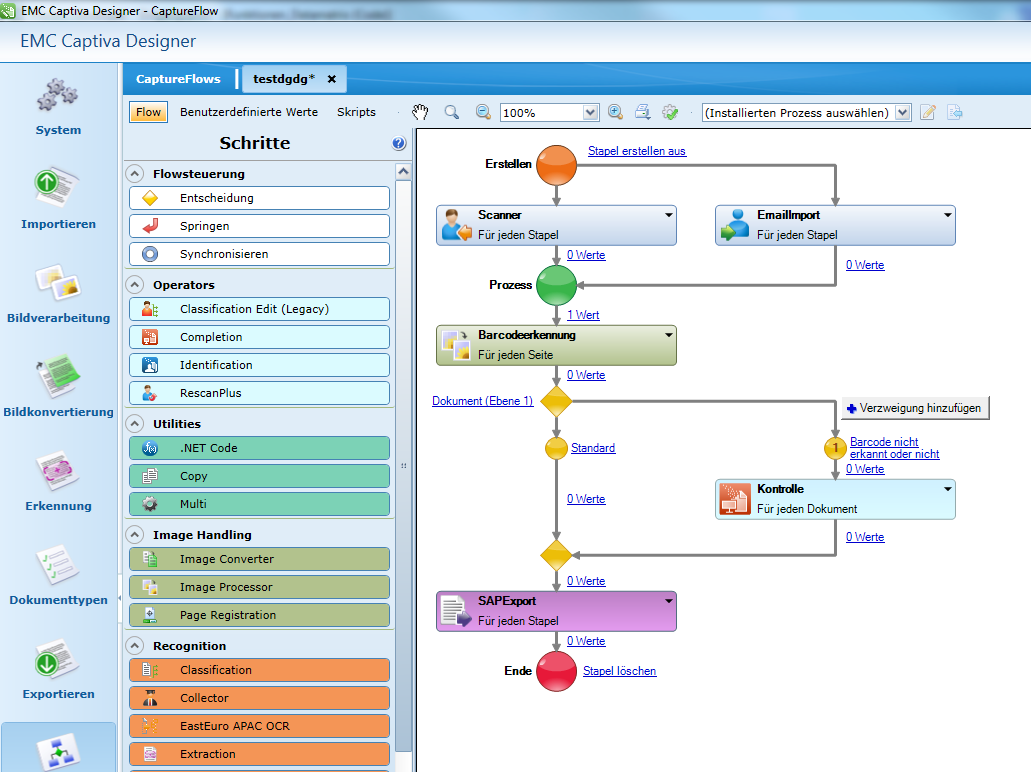
Captiva Capture from OpenText offers various input management modules for digitizing (scanning), importing, processing and exporting documents. Classically, the user has a large stack of hundreds of invoices or other forms at his workstation and wants to process them accordingly. Surely, anyone can imagine that it is not efficient to scan and process each document individually.
Exactly here Captiva Capture creates direct remedy: The user simply packs a whole stack consisting of all documents into the scanner and does not need to worry any more about the reading of customer numbers, insurance numbers, invoice amounts or other important contents. Everything happens automatically!
Thus, the scanning is really one of the smallest parts in the Captiva world. The development of the corresponding processes for the sharing of the different documents after providers and the reading out of relevant contents is the clearly bigger factor. Exactly this is where I come in. My job as a developer is to make sure that the user has as little to worry as possible.
As a developer tool, Captiva provides a range of functions and modules, which make a flexible process development possible and represent almost all requirements in the area of the input management. Beside the scanning also E-Mails and files can be used by a file path as source for the import.
What exactly does Captiva do now, which tasks have I thereby as a developer and what does the user do in the end? In addition more in the following simple practice scenario.
Starting example:
An insurance company receives several thousand letters a day from hospitals that have treated patients accordingly. Invoices can be structured differently. Once the documents have landed in the system, they are exported to SAP and archived.
What does the user have to do?
In this process, the employees of the insurance company are divided into two task areas: scanning and checking.
The scan-employees prepare the invoices by combining and scanning all documents from all vendors in one batch. If no invoice number and e.g. no date of birth of the patient could be automatically read out (poor quality or because the data on the document is missing), the invoice is sent to an employee for checking. The employee enters the corresponding data manually or uses a veto.
What should the developer be aware of?
With the help of Captiva and the corresponding modules, I first make sure that the e-mails are imported. Various security guidelines must also be implemented so that no “nonsense” gets into the system.
Afterwards all documents of scan, e-mail and fax are prepared and checked for quality. it happens more often that many data on the forms are not legible (black spots, poor print quality and blurred content). Here it is necessary to create remedy with various filters and “rules”. Empty pages should be deleted.
The next step is to classify the invoice document. By means of different criteria (which are taught to the system before) Captiva recognizes, which creditor it concerns. Thus it is exactly known in which place the invoice number and the date of birth are to be searched.
If no valid data is found, I bring the document to the appropriate application for checking and validate the user’s entry. Only if the mandatory fields are filled and correct I prepare the document including data for the SAP export.
Parallel to the normal “invoice run”, I write various data into an internally managed statistic: How often does it happen that a user has to check? Why was it necessary to check (was there no invoice number or was it incorrect)? From this data, the company can identify optimization processes and implement them together with me.
That was just a small example…
This example shows, however, that in many and especially in larger companies, much more than just scanning and checking runs in the background.
In the background, everything is first developed, tested and trained with the help of Captiva. In everyday practice, much greater hurdles have to be overcome. Especially if an enterprise uses many different document types and processes internally for the processing and archiving of the forms. It does not matter which requirements are made: Everything can be set up or developed. No matter whether documents are to enter or exit the system. How they are read or processed.
Small challenges in everyday life
A small overview of typical “problems” during development makes it clear again that even small things sometimes become a challenge.
- Picture qualities: If there are several thousand different documents, the preparation should be done wisely. Many things that are not legible can be improved.
- Filtering out documents that should not be imported at all (e.g. if the user scanned something wrong).
- Insurance number: It should always be ensured that no other number consisting of the same combination of numbers is read out instead of an insurance number. For example, a fax number has already been read out instead of the insurance number.
- E-mail import: It must be verified exactly which documents and contents are valid. For example, images such as Twitter or Facebook logos may not be processed in a signature or imported as a document.
- Faxes are often page-turned. It must be ensured that the document is correctly displayed and archived. The company should also be able to handle errors appropriately in order to react accordingly.
- What happens if documents are not classified or barcodes are not read?
For those who did not concern more closely with Captiva, the processing of the data appears as quite natural. Nevertheless I hope very much that my Blog contributes to it to point out what the software solution from the house OpenText offers and which challenges one places oneself as a developer thereby. It is simply fun to create a process that ideally takes over all tasks after the scan or import completely and no manual intervention of the users is necessary anymore. From receipt of the invoice to payment. All completely automatic – there is certainly more time for a good cup of coffee between meals 🙂



0 Comments