
What OpenText announced at Enterprise World 2019 in Toronto for the InfoArchive Roadmap has already been realized by fme: Setting up a container-based infrastructure for OpenText InfoArchive.
The majority of IT managers are now aware of the advantages of a container-based infrastructure over the usage of virtual machines that were most commonly used in the past (Docker – the “Gamechanger”).
Therefore, it is understandable that they want to benefit from this technology when designing new IT systems. For this reason, fme’s concept of setting up InfoArchives as a containerized on-premises environment has convinced the client when he was planning a new company-wide archiving platform.
Even though OpenText does not yet provide ready-to-use containers for InfoArchive, the platform is very well suited for operating in containers due to its modular architecture.
Deployment of Docker Images
InfoArchive is composed of three main logical components:
- IA Server – The business logic
- IA WebApp – Web application that serves as the user interface
- xDB Nodes – databases containing records (structured data), search results, retention data and system data
We created one Docker Image for each of these three components. We went with a CentOS-based base image and called it “fmeIABasisImage” (see picture below).
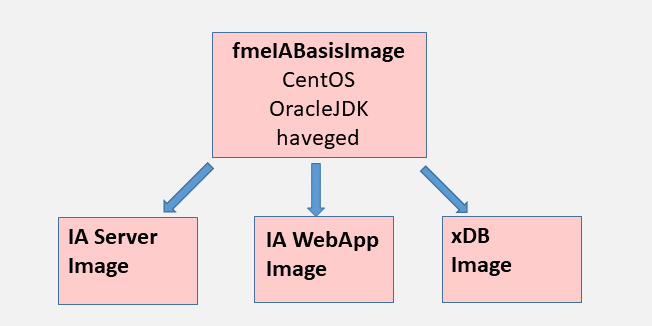
The images are built using Dockerfiles. Besides CentOS as the operating system we installed all other software components required to run OpenText InfoArchive, such as OracleJDK and haveged , in the base image.
The following steps need to be executed for the IA Server Image:
- Load our basic image
- Copy InfoArchive Install package into the container and unpack it
- Load project-specific configuration files for IA Server
- Set the JAVA_HOME variable
FROM fmeIABasisImage:latest
COPY infoarchive.tar.gz /opt
RUN cd /opt && tar -xzf /opt/infoarchive.tar.gz && rm /opt/infoarchive.tar.gz
COPY Config/* /opt/infoarchive/config/iaserver
ENV JAVA_HOME /usr/java/jdk1.8.0_202-amd64/jre
Code: Dockerfile for IA Server Image
For the sake of completeness, the Dockerfiles for the IA WebApp Image and the xDB Image are also listed below, but they are not explained further. Regarding the Dockerfile for the IA WebApp image the installation of the LanguagePack in line 5 should be mentioned. It provides a German version of the user interface.
FROM fmeIABasisImage:latest
COPY infoarchive.tar.gz /opt
RUN cd /opt && tar -xzf /opt/infoarchive.tar.gz && rm /opt/infoarchive.tar.gz
COPY languagepack.tar.gz /opt/infoarchive
RUN cd /opt/infoarchive && tar -xzf /opt/infoarchive/languagepack.tar.gz && rm /opt/infoarchive/languagepack.tar.gz
COPY Config/* /opt/infoarchive/config/iawebapp/
ENV JAVA_HOME /usr/java/jdk1.8.0_202-amd64/jre
RUN cd /opt/infoarchive/languagepack && ../bin/ant
Code: Dockerfile for IA WebApp Image
FROM fmeIABasisImage:latest
ENV license=…
XHIVE_DATANODE=/data/xdb/XhiveDatabase.bootstrap
XHIVE_SERVER_ADDRESS='*'
COPY infoarchive.tar.gz /opt
RUN cd /opt && tar -xzf /opt/infoarchive.tar.gz && rm /opt/infoarchive.tar.gz && cd infoarchive && tar -xzf first-time-setup/xDB_11_1_11_IA.tar.gz
COPY Config/* /opt/infoarchive/xDB/
Code: Dockerfile for xDB Image
Creation of the Docker Container and Architecture of the IA Environment
Docker containers are the running instances of a docker image. To assign parameters such as port numbers we set and pass environment variables to the container. In our initial setup, we created two IA Servers and two IA Web App Servers as well as four xDB Nodes (one node each for System Data, Structured Data, Retention Data and Search Result).
Persistent data can be stored on all InfoArchive approved storage devices, including NAS/SAN, Isilon, ECS, AWS S3, Glacier, Archive Center or other custom storage systems.
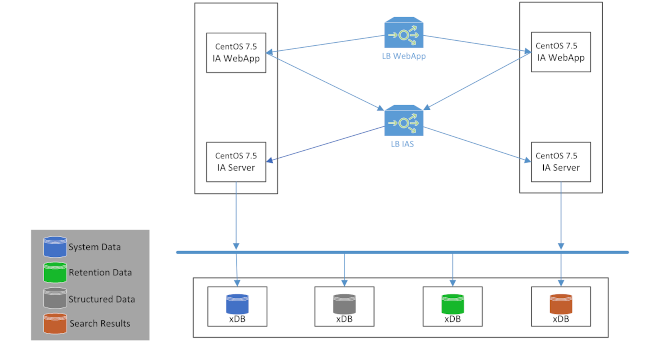
We started the containers during the development phase with the Docker run command. Since they need to communicate with each other, they are connected with option -link. In the case of the IA server, the service is started in the container via a shell script.
docker run -d --link xdb --link xdb-retention --link xdb-search --link xdb-structured --name ia-server -v InfoArchive:/etc/IA -p 8383:8765 ia-server:16.5 /bin/sh -c "/opt/infoarchive/config/iaserver/run.sh"
Dockerruncommand for an IA Server container
In the production environment, the containers can now be monitored and restarted automatically with the help of GitLab and orchestration software such as Kubernetes or Docker Swarm.
Benefits
- The environment can be easily scaled by adding containers with specific tasks (e.g. exclusively for ingestion). As the data volume grows, additional xDB nodes can also be added
- In many cases, an update of the software can be executed by simply changing the docker files. For example, the operating system can be updated by changing the base image for all components.
- Additional software can be easily installed by small script adjustments, such as copying from an external source into the container
Outlook
What we can conclude is that OpenText InfoArchive already works well with container technology. Especially the reduction of complexity as well as the high degree of reusability offers many advantages for projects. We are looking forward to see how the container images delivered directly from OpenText in the just recently released Version 16.7 look like. Stay tuned.



0 Comments