
Who loves reading docs? Probably not that many developers and engineers. Coding and developing are so much more exciting than spending hours reading tons of documentation. However just recently I was taught again that this is one of the big misconceptions and fallacies – probably not only for me.
AWS provides an extensive documentation for each service which contains not just a general overview but, in most cases, a deep knowledge of details and specifies related to an AWS service. Most service documentations consist of hundreds of pages including a lot of examples and code snippets which are quite often helpful – especially related to IAM policies. It is not always easy to find the relevant pieces for a specific edge case or it might be missing from time to time, but overall AWS have done a great job documenting their landscape.
Service quotas which exist for every AWS service are another part which should not be missed when either starting to work with a new AWS service or to use one more extensively. Many headaches and lost hours spent to debug an issue could be avoided by taken these quotas into account right from the start. Unfortunately, this lesson is too easy to forget like will be shown in the following example.
In a recent project, AWS DataSync was used to move about 40 million files from an AWS EFS share to a S3 bucket. The whole sync process should be repeated from time to time after the initial sync to take new and updated files into account. AWS DataSync supports this scenario by applying an incremental approach after the first run.
One DataSync location was created for EFS and another one for S3 and both where sticked to gether by an DataSync task which configures among other things the sync properties. The initial run of this task went fine. All files were synced after about 9 hours.
Some days later a first incremental sync was started to reflect the changes which had happened on EFS since the first run. The task went into the preparation phase but broke after about 30 minutes with a strange error message:

“Cannot allocate memory” – what are you trying to tell me? No memory setting was configured in the DataSync task definition as no agent was involved. The first hit on Google shed some light on this problem by redirecting me to the documentation of AWS DataSync.
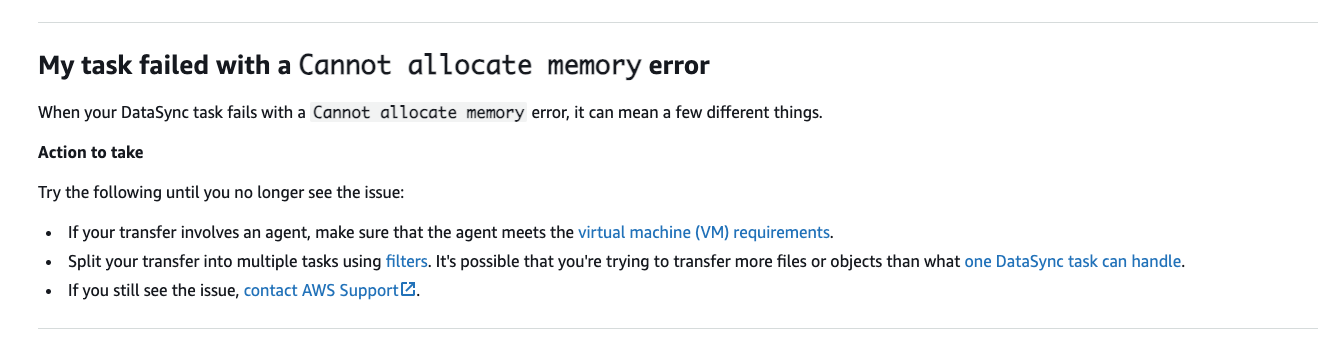
which contains a link to the DataSync task quotas:
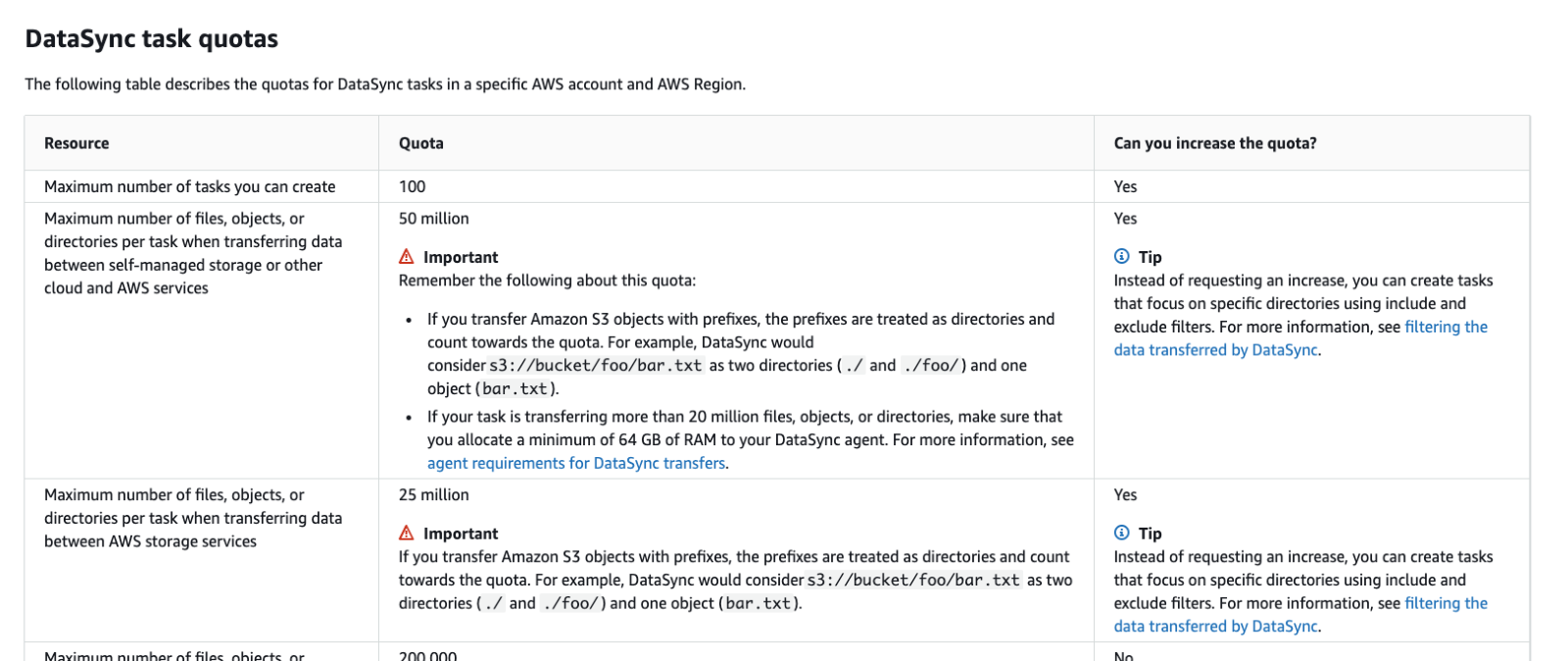
Apparently, 40 million files are way too much for one task as only 25 million are supported when transferring files between AWS Storage services. A request to the AWS support confirmed as well that problem was related to the large number of files. I have no idea why the initial run was able to run through but at least the follow up one failed. Splitting up the task into several smaller ones solved this issue so that the incremental run could finally be succeeded as well. Nevertheless, some hours were lost even though we learned something new.
Lessons learned – again:
- Embrace the docs – even though they are really extensive!
- Take the service quotas into account before starting to work and while working with an AWS service. They will get relevant one day – possibly earlier than later!
- AWS technical support really like to help and is quite competent. Do not hesitate to contact them (if you have a support plan available).



0 Comments