
How to define an agile Object Model
Document’s metadata
Let’s start our discussion on how any company may receive a new document. It could be either in electronic form or in a physical form that requires scanning and transformation to an electronic version. So before storing this document inside any document management system, let’s think together on how to enhance this document with some metadata that helps retrieving it easily in the future.
Most people may think on creating a separate document type with a set of metadata for each type they have (for example: Document type named invoices with defined attributes like invoice date, invoice number, invoice amount, client name, … etc.) but this approach increases the administration tasks for all of those defined doctypes. So, let’s start thinking about defining an agile object model that fits a wide range of different document types).
Q: What metadata could be common across any type of document?
A: Document Date & Document Number
Exactly, for example:
- If we have a document of type “Invoice” then we have Invoice Date and Invoice Number.
- If we have a document of type “Contract” then we have Contract Date and Contract Number.
- If we have a document of type “Certificate of Calibration” then we have Certificate Date and Certificate Number.
Q: How can I classify my document type?
A: Great question, Let’s start with this concept. Add 3 metadata that define the document as follows:
- Business Unit (Department/Site)
- Document Type
- Sub-Document Type
Example 1: Assume we have a department called “Finance” that manages different document types so here is a scenario on how to manage those documents by classifying them into Document Type and Sub-Document Types:
- Business Unit (Department/Site): Finance
- Document Type: Purchasing
- Sub-Document Type: Requisition, Purchase Order & Procurement Card
Or
- Business Unit (Department/Site): Finance
- Document Type: Accounts Payable
- Sub-Document Type: Payment Request, Credit Memo & Disbursement Voucher
Example 2: Assume we have a department called “Manufacturing” that manages different document types so here is another scenario on how to manage those documents by classifying them into Document Type and Sub-Document Types:
- Business Unit (Department/Site): Manufacturing
- Document Type: Certificates
- Sub-Document Type: Certificate of Calibration, Certificate of Analysis & Certificate of Inspection
Or
- Business Unit (Department/Site): Manufacturing
- Document Type: Supplier Records
- Sub-Document Type: Contracts, Master Service Agreement, Quality Assurance Agreement, Performance Records & Miscellaneous
Q: What other metadata could be used to enrich the search feature?
A: There are many other metadata that could be used but let’s focus on generic ones that can be used to capture any other information listed on the document that we intend to archive
- Description/Comments/Keywords
- Reference Number (can be used to capture Account number, Part number, Lot number, Manufacturer number, Serial number, … etc.)
- Reference Name 1 (can be used to capture Vendor name, Client name, Patient name, First name, … etc.)
- Reference Name 2 (can be used to capture Last Name or any other names located on the document)
- ID (can be used to capture Employee ID, User ID, … etc.)
- Product/Project (can be used to capture Product Name, Product number, Project Name, Project number, … etc.)
- Box Number (can be used to reference the Box number where the original physical document is located)
- Document Source (can be used to capture the source of the document like Scanning, received by email, fax, Manual Import, added by Job, … etc.)
Q: What other metadata could be added if I am scanning physical documents?
A: Here is a list of metadata that can be used to capture auditing information during scanning process:
- Scan Operator
- Scan Date
- Index Operator
- Index Date
- Scanned Pages
- Batch Name/ID
Great! Now, we came with a list of generic metadata that can be used to easily classify & enrich any document.

Folder Structure
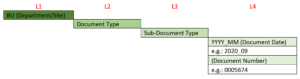
Simply, we can use the “Type” attributes on defining an easily readable folder structure as follows:
- Level 1 (L1): BU (Department/Site)
- Level 2 (L2): Document Type
- Level 3 (L3): Sub-Document Type
- Level 4 (L4): can be either structured to be YYYY_MM (Document Date), or Document number (if unique).That’s why all of the above attributes should be mandatory in order to be used on defining the folder structure.
How to define an agile Security Model
Permission Set
Another interesting topic which is how to define an agile security model that can easily grants access to documents within an organization based on users’ role.
Let’s build our security model assuming that a user within a business unit (Department/Site) can either access all defined Document types within that BU, or can access specific document type(s).
Here is the suggested permission set on each Level of the defined Folder structure.
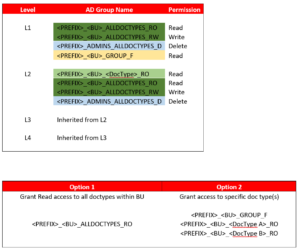
Note: <BU> & <DocType> are placeholders where:
- <PREFIX> can be replaced with system name or any other prefix to help syncing AD groups based that starts with this prefix.
- <BU> represents Business Unit (Department or Site).
- <DocType> represents defined document type.
Let’s take an example of having a “Finance” BU with 2 document types (Purchasing & Accounts Payable) with some sub-document types, and translate the above concept into some AD groups:
Type Matrix:

Folder Structure:
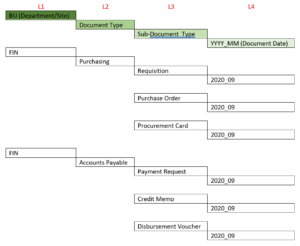
Suggested AD Groups:

Note: you can use “DCTM_*” to filter AD groups for LDAP synchronization.



0 Comments