
With migration-center version 3.9 we will introduce a new scanner for CSV and Excel files. Previously, you could use our database scanner in order to scan data from CSV and Excel files, but this solution relied on the Java JDBC-to-ODBC bridge, which was discontinued with Java 8. We have taken this as an opportunity to introduce a new scanner for CSV and Excel files and also added a very powerful feature that we call “enrichment scanning”.
The new CSV and Excel scanner supports two operating modes: normal mode and enrichment mode. With normal mode, you can scan data from CSV and Excel files as you used to do with the database scanner (only with a much better performance when scanning large files). With enhancement mode, you can scan data from CSV and Excel files and add that data to a previously scanned scan run in order to enrich that scan run with the data from the CSV or Excel file respectively.
WHAT IS THE USE CASE FOR ENRICHMENT MODE?
Imagine that you have a business application, which combines documents in your document management system (DMS) and additional data from – for example – a database system (DB).
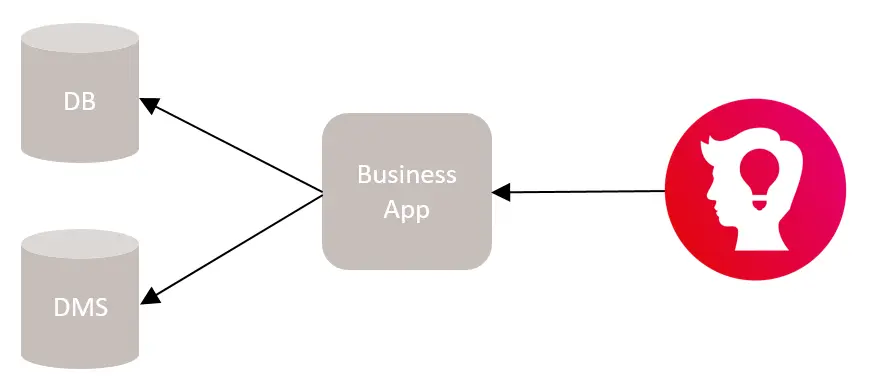
Business Application
If you want to archive the data of this business application, it would certainly make sense to consolidate the data from all systems into one archive record. Or you may even want to replace your existing application with a new one while consolidating data from different systems.
HOW DOES ENRICHMENT MODE WORK IN DETAIL?
The enrichment mode works in two steps. In the first step, you scan the documents and their metadata from the document management system with the appropriate migration-center scanner. migration-center will store the metadata of all scanned objects in its database.

First step
Each scanned record has a unique identifier in the migration-center database, called ID-in-source-system. For an OpenText Documentum source system, the ID-in-source-system would be the r_object_id of the documents.
In the second step, you export the additional data from the third-party system into a CSV file and scan this file with the new CSV scanner in enrichment mode. You have to specify the ID of the scan run from step 1 in the settings of the scanner. The migration-center will then check if the ID-in-source-system of a scanned record from the CSV file matches any ID-in-source-system in the specified scan run. If yes, it will add the data from the CSV file as additional source attributes to the existing record in the scan run. If not, it will simply ignore the record. The result will be a consolidated record in the migration-center database, as shown in the figure below.

Second step
Of course, you can repeat the second step several times, in case you need to consolidate data from more than one additional system.



0 Comments