One of our existing customers has been using Jive as a social intranet for years. A social intranet, like many other systems, thrives on user interaction. A higher usage leads to more exchange and identification of employees. As these platforms grow, there is typically the challenge of a lot of content being created and users having to navigate through a jungle of communities and content. So how can you ensure that users see the content that suits them? The magic word is “recommendation systems”.
There are already enough examples in the consumer sector for recommendation systems. Amazon Prime offers film recommendations that match user behaviour e.g. “Customers who have seen this film have also watched these films”. In the Amazon e-commerce shop, product recommendations for similar products are displayed to the buyer. But how does a company go about integrating a well-functioning recommendation system into its own product? Amazon has recognised the potential and since 2019 has been offering AWS Personalize, a specialised service in the AWS cosmos, which they use themselves and now also make available to customers.
AWS Personalize at a glance
With its Personalize service, AWS offers a complete solution for building and using recommendation systems in its own solutions. The service, which is now also offered in the Europe/Frankfurt region, has been available since 2019 and is constantly being improved. Only last year, major improvements in the area of filters were added to the product.
AWS Personalize allows customers to create recommendations based on an ML model for platform or product users. The following activities are abstracted and made particularly easy by AWS Personalize:
Import business data into AWS Personalize
Continuous training of models with current data
Read recommendations with filtering capabilities from AWS Personalize
You might think that recommendation systems based on machine learning are old news and that you can do it all yourself anyway. Machine learning has been around for a few years now, and with it the possibility of developing such recommendation systems yourself.
But the difference is: AWS Personalize takes the complete management of Machine Learning environments off the users’ hands and allows to take first steps here very quickly. And we don’t need the best ML experts on the team, because AWS Personalize takes a lot of more complex issues off our hands. Why it’s still good to understand Machine Learning is shown by the challenges.
AWS Personalize makes it easier than ever for us to create recommendations. From a technical perspective, everything seems easy to master. We find challenges mainly in the clear delineation of the use case and the meaningfulness of the recommendations.
The recommendations should be as clearly delimited as possible for a use case. This influences both the selection of data and the structure of the data model and schema.
A recommendation system lives from the meaningfulness and topicality of the displayed recommendations. If, for example, I make recommendations to a user that he already knows, are 2 years old or are not relevant at all, I lose his interest and trust. Recommendations are therefore first viewed critically and must therefore be convincing from the outset, even if this is of course partly viewed subjectively.
Therefore, we need to ask the following questions from the beginning:
Which of my data will help improve the model?
What statements do I want to make with the recommendations in the first place?
How can I validate the recommendations for correctness?
How can I make recommendations to the user that they don’t already know?
It is very important to constantly validate the recommendations created by AWS Personalize. At the start, it is important to validate the recommendations manually, i.e., to check randomly whether the recommendations appear meaningful to a user at all. Recommendation is therefore to start with a recommendation system whose validity can be easily checked. In order to give a user recommendations that he or she does not yet know, it is necessary to work a lot with recommendation filters, so that favourites of users or content that has already been seen do not appear again.
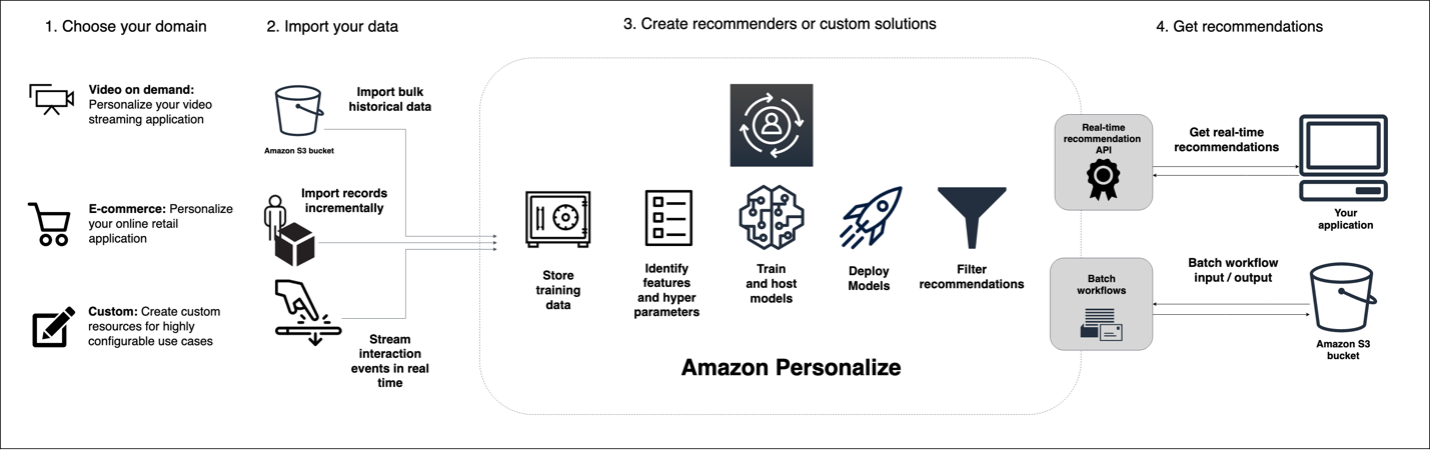
Process View
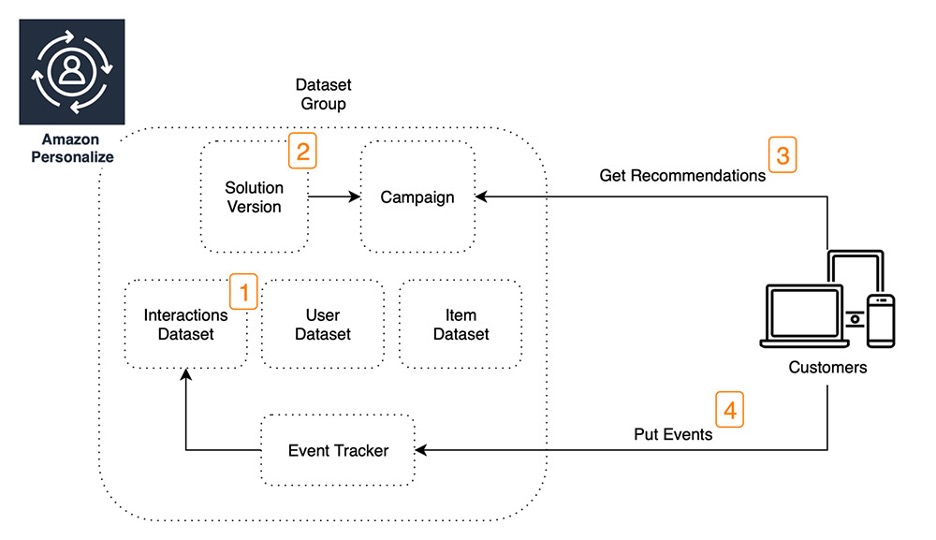
Now how do we make Personalize create recommendations for us? To do this, there are a few steps to complete.
First, you should select a domain that best matches the use case (1).
In case of a user-defined use case, data models are defined afterwards. Importing your own data into Personalize is done once or continuously based on the defined data models (2).
Amazon Personalize uses the imported data to train and provide recommendation models (3).
To query recommendations, both an HTTP-based real-time API for one user and batch jobs for multiple users can be integrated (4).
Now let’s take a look at these data models.
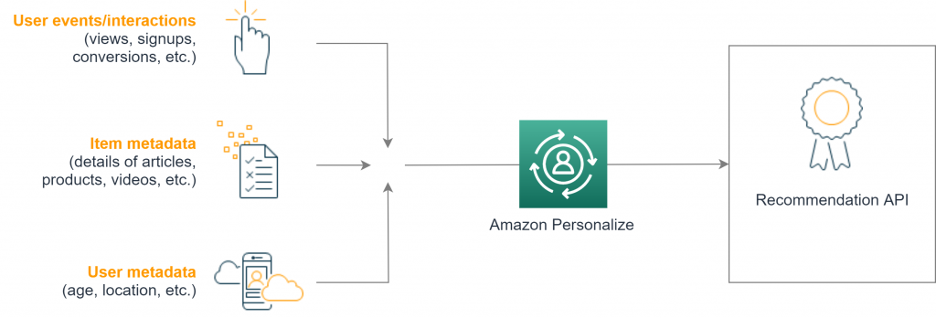
Data models
In addition to the e-commerce and video use cases, AWS Personalize offers the option of mapping your own use cases (domain). The bottom line is that it is always about the following data sets:
These datasets form a dataset group and are used as a whole in Personalize. Crucial here are the interactions that are necessary for most ML models and are used for training. A short example will illustrate this data model:
“A fme employee reads the blog post “AWS Partnership” on the social intranet and writes a comment below it.”
User: fme employee
Item: Blogpost “AWS Partnership
Interactions: read | comment
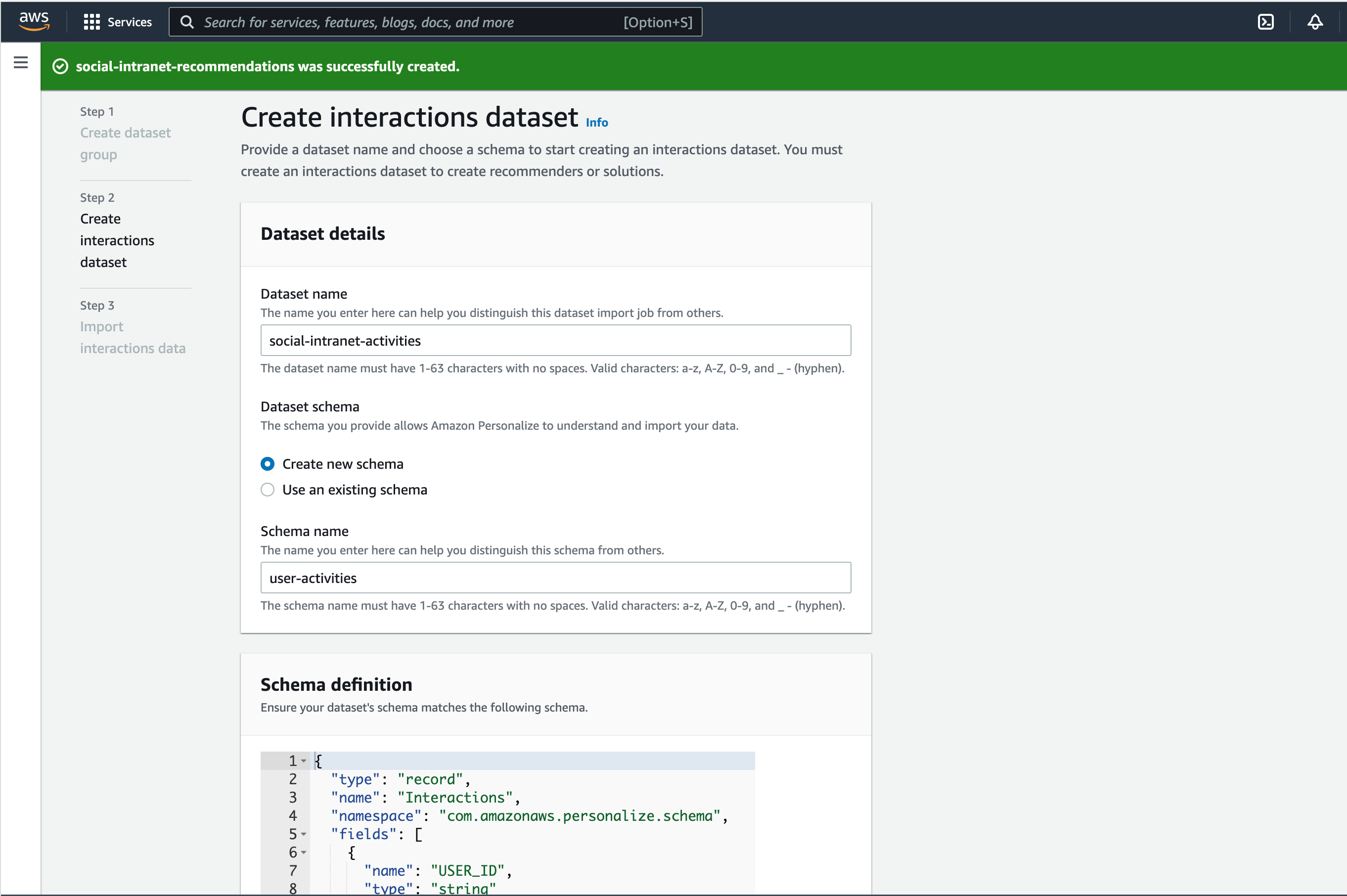
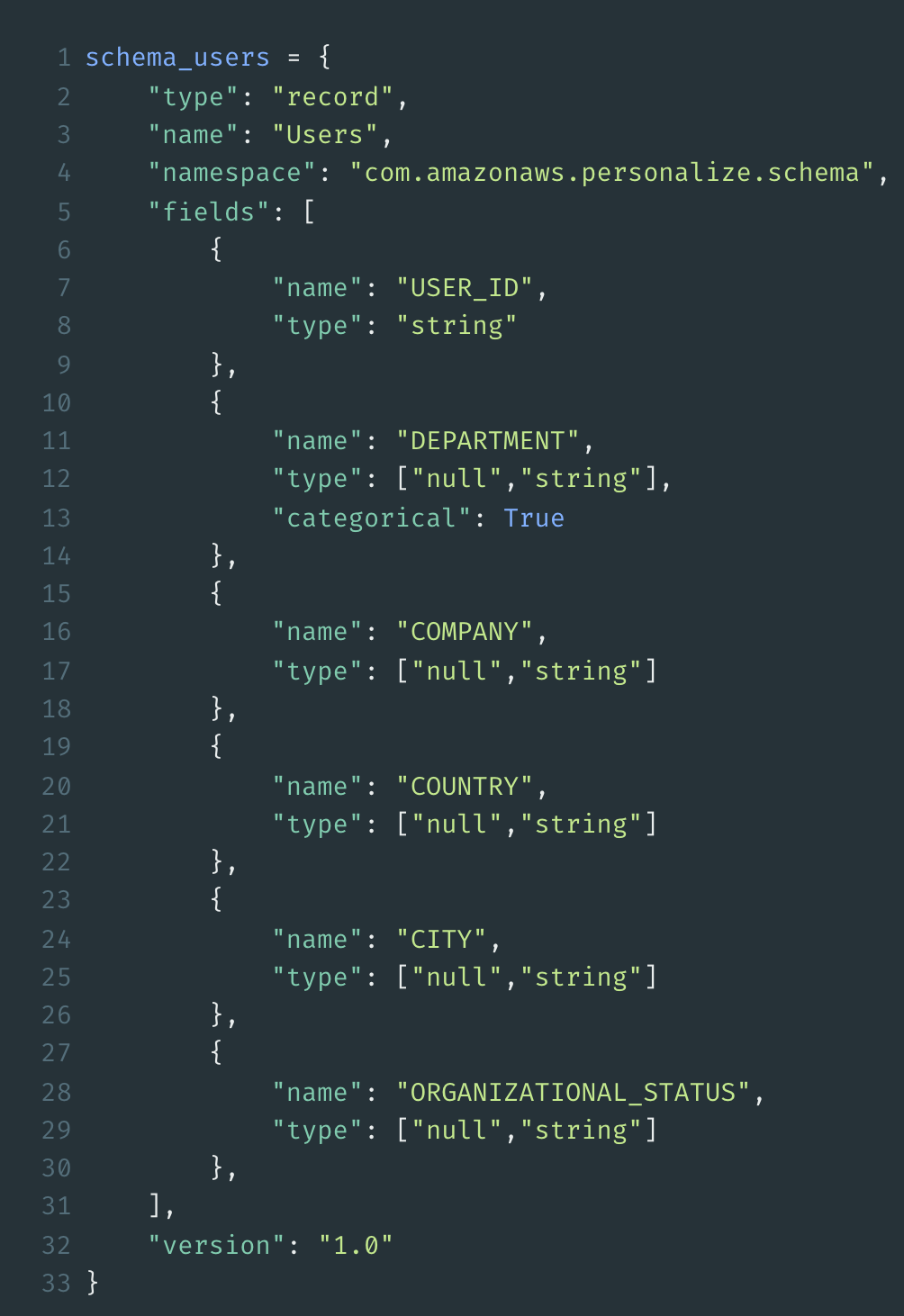
For this data a developer can define his own schema – one schema each for Interactions, Users and Items.
The following is an example schema for a user with 6 fields. These fields can be later used to get recommendations for content of specific users, e.g. users from a specific company or country.
When importing data, this schema must then be followed. All three datasets have mandatory attributes (e.g. ID) as well as additional attributes that help to refine the ML model so that the recommendations can become even more precise. The additional attributes can be textual or categorical. They can also be used to filter recommendations.
However, there are a few restrictions in modeling that you need to be aware of, such as the restrictions on 1000 characters per metadata. This is especially important if you want to model lists of values.
The quality of recommendations are dependent on the data provided. But how does the data get into the system?
The import of data always takes place in these data pots, so-called datasets (see above) – there is exactly 1 dataset each for Users, Items and Interactions. These datasets are combined in a dataset group.
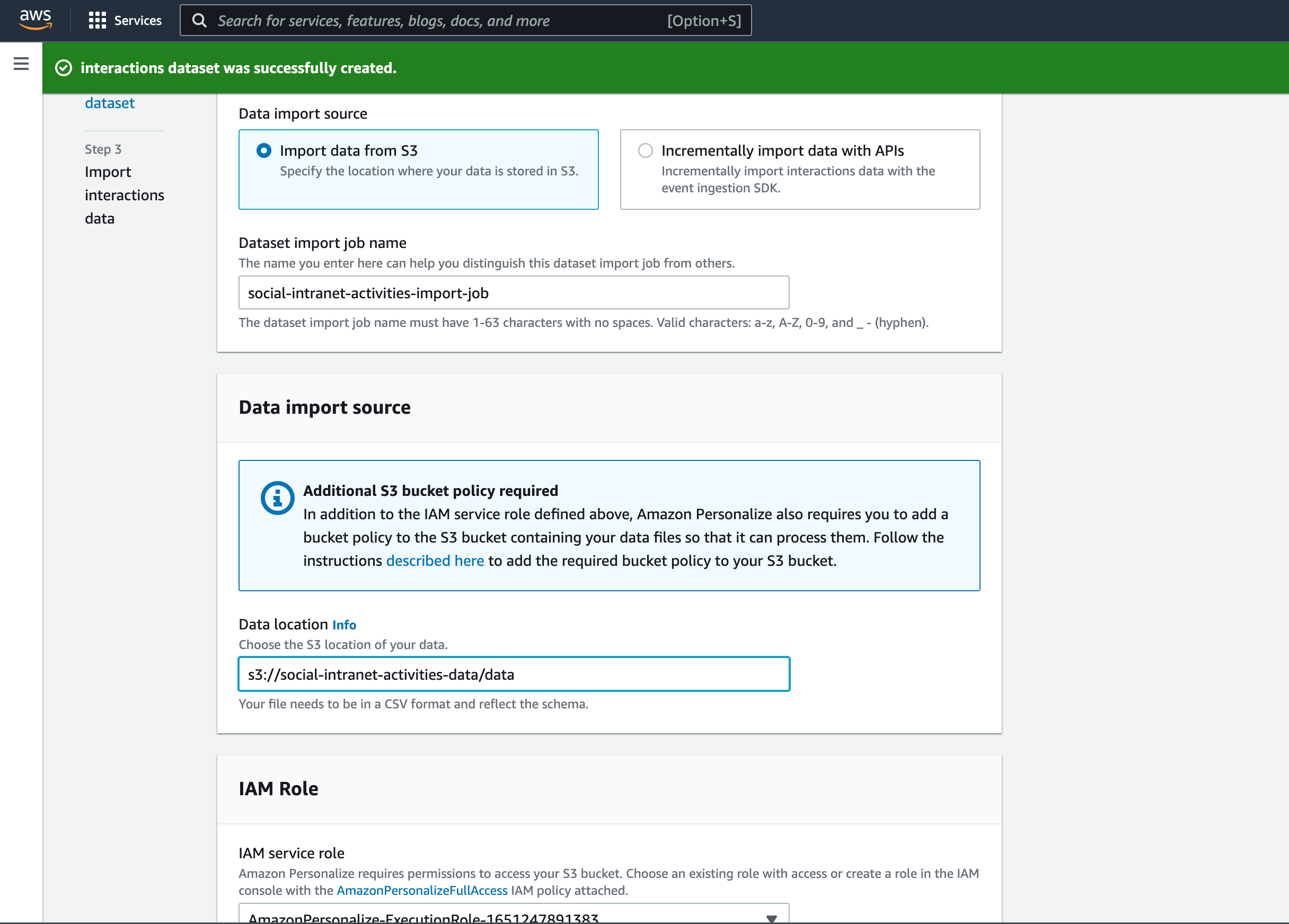
To be able to train the ML model, the data sets have to be imported at the beginning (bulk import via S3). It is also possible to update the data continuously (via an API), which ensures that the model can always be improved.
When you start with AWS Personalize, you usually already have a lot of historical data in your own application. This is necessary because recommendations only “work” meaningfully once a certain amount of data is available (aswithany ML application).
Here it is recommended to use the bulk import APIs of AWS Personalize. For this, the data must first be stored in S3 in CSV formatand according to the previously defined schema. Then you can start import jobs (1 per record) via AWS Console, AWS CLI, AWS API or AWS SDKs.
For continuous updating of the Users and Items datasets, AWS Personalize provides REST APIs that can be easily used with the AWS Client SDKs.
A so-called event tracker can be used forupdating the interactions. This previously created tracker can be used for a large amount of events within a very short time to get data into the system via HTTP.
Once the initial data is imported, AWS Personalize can now use this data in the form of the Dataset Group to train a model. To do this, you can first create a Solution, which is a “folder” for models. This sets the Recipe that Personalize should use.
The recipe represents the ML model, which is then later trained (as a Solution version) with user-defined data. There are different types of recipes that offer different types of recommendations. For example, USER_PERSONALIZATION provides personalized recommendations (from all items) and PERSONALIZED_RANKING can provide a list of items with rankings for a particular user. Some recipes use all three data sets and some use only parts of them (e.g. SIMS does not need user data).
After creating a solution, it can then be trained with the current state of the data sets, resulting in a solution version. Depending on the amount of data, this can take a little longer – our tests showed runtimes of around 45 minutes. A solution version is the fully trained model that can be used directly for batch inference jobs or as the basis for a campaign – a real-time API for recommendations.
Use recommendations in your own application
Now it’s time to integrate recommendations into our own application. AWS provides a REST interface that allows us to retrieve recommendations from AWS Personalize in real-time. This makes it easy for us to integrate with any system
Recommendations in AWS Personalize are always user-related. Recommendations can therefore look different for each user – but can also be the same for certain recipes, as in the case of “Popularity count”.
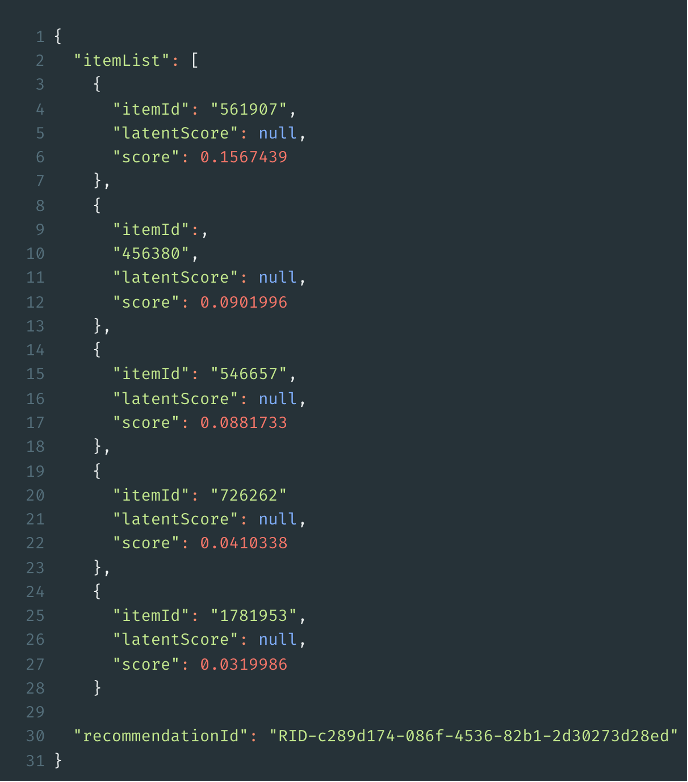
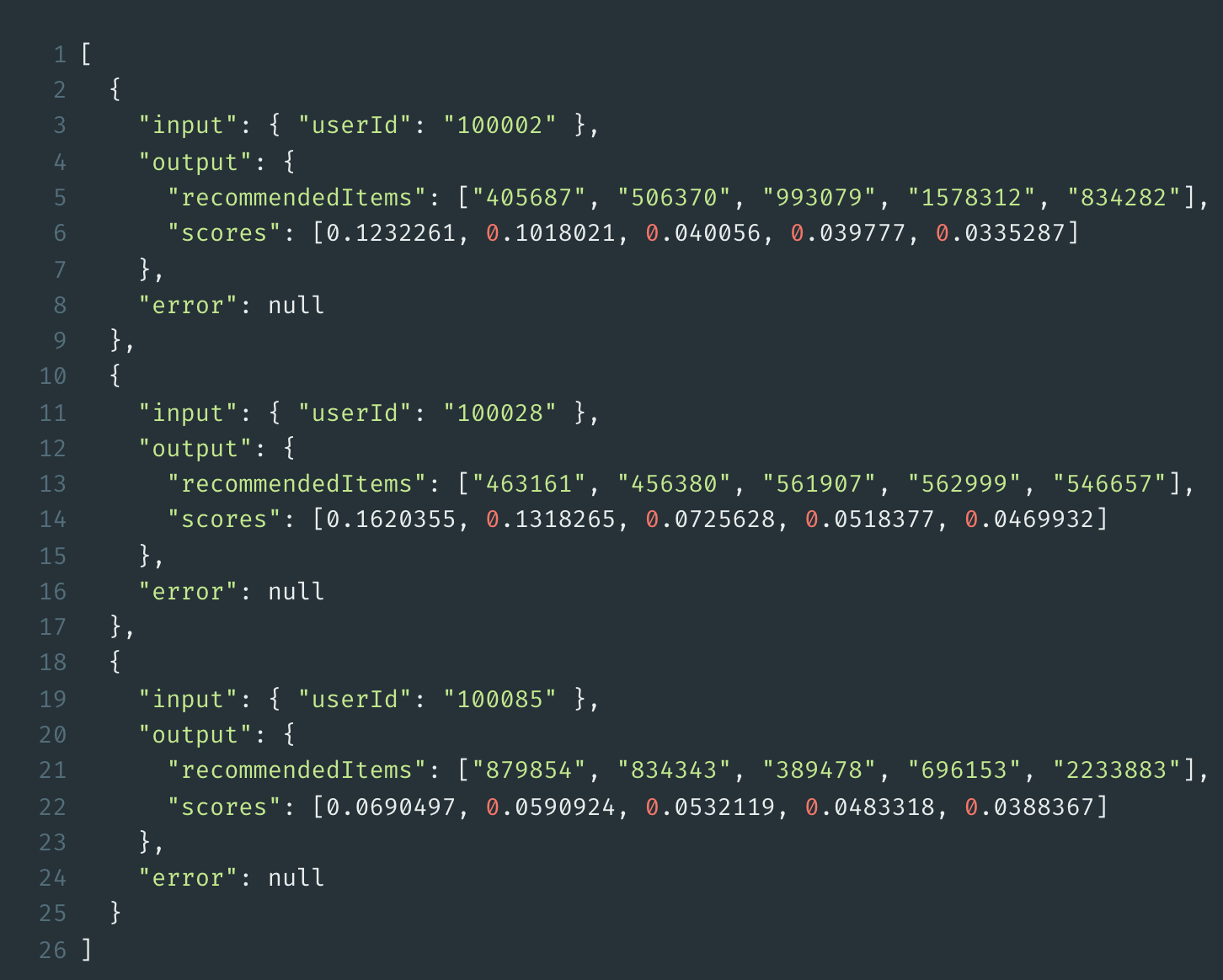
The response is a list of recommendations in the form of IDs of the recommended items, each with a score. The items are uniquely referenced via the ID.
These recommendations can now be evaluated in your own application, linked with the content from your own database and then displayed to the user in a user interface. The performance of the query (at least for smaller amounts of data) is so good that this query can be done live. However, one can also think about keeping the results of the query for a while per user, so as not to have to constantly request the service.
Example of a response for a recommendation request
If you need recommendations for a large number of users for mailings, batch jobs (batch inference jobs) can efficiently create these recommendations in the background. These batch jobs can be “fed” with the UserIds – the result are recommendations for each user within one big JSON file.
Example for a result of the batch inference jobs
Is Personalize worth the effort?
The pricing model of the service can be quite demanding, so it is advisable to define in advance a result that you want to achieve with appropriate recommendations and resulting follow-up activities or repeat business.
As a guide, to get individual recommendations for individual users in the Personalize Batch, we assume about 0.06 ct per recommendation for the user. That doesn’t sound like a lot, but with several hundred thousand users and individual recommendations, it’s part of the overall consideration. Depending on how often and to what extent batch runs for mailings etc. take place, it can get expensive. And the instances AWS uses for batch runs are very large and very fast. We created several batch jobs for mass exporting recommendations for 200k users for testing purposes. The batch jobs then ran overnight. We incurred costs of several hundred Euros – we had probably underestimated the numbers in the AWS Calculator a bit.
If referrals have a positive impact on the business and thus directly generate more sales for the customer, it can pay off very well. But what if my recommendations do not have a direct positive impact on my sales? One reason could be to bind customers more closely (subscription model) – in the long term, this will in turn lead to more sales, but perhaps not in the short term.
Summary
AWS Personalize is a service that makes it very easy to get started with recommendation systems. As a development team, all you have to do is deliver the data in the right format and pick up the recommendations. It doesn’t get much easier than that from a technical perspective.
AWS Personalize can therefore be used well to extend existing systems without having to make deep changes. With the ability to create custom data models and tune the different ML algorithms, you can apply AWS Personalize to a wide variety of scenarios.
The real work is in finding meaningful use cases, delineating them from one another, and providing the system with the right data.
As always, this comes at a price. Is it worth it for them? Let’s find out together.
References and Links
Below are a few more links to help dig deeper into the topic:




0 Comments