
Recently at the client: a KPI dashboard is to be set up. We are currently conducting an initial discussion, presenting existing solutions and the software. A dialogue develops, first about technical content, then about the functions of the software, which very often leads to a question: “We can make changes ourselves and create graphics, can’t we?” Hmmmmm. Yes and no. Moreover, very important: “In any case we have to be able to load data from Excel, is that possible?” Yes… theoretically, yes. Then comes the next classic: “Besides, the processes in the IT department take too long, we can’t wait weeks for new KPIs to be visualized.”
We find these requirements in the same way or similarly with most of our clients whom we advise in the Business Intelligence (BI) environment. Many have a great need to be able to create and edit graphics and data themselves. Then the term “Self-Service BI” is often used, although not everyone has the same understanding of what is hidden behind the term and which topics are still behind when it comes to let the users work. The fact that there are always inquiries about this also shows how important it is for our customers to be able to take action themselves. But why is that so?
Our blog series is intended to shed some light on this issue – we want to clear up the terms and explain by way of example what self-service BI means to us in practice and what benefits it can bring to our clients. In this sense: please help yourself and enjoy reading!
What does self-service mean in concrete terms?
Anyone, who “somehow” has to do with BI, will have stumbled upon the term at some point and will have thought about it for themselves, possibly even working in an environment in which a self-service BI environment is set up. How exactly is the topic officially defined?
The research and consulting institute BARC [1] and the manufacturer-independent community TDWI [2] describe self-service BI as follows:
- Self-Service BI describes the activities that are performed by business users instead of passing them on to the IT department
- The users (from a non-technical environment) have direct access to the data in order to gain self-directed knowledge and to carry out analyses and visualisations
- This is done by using BI tools that are simple enough in the application so that users do not have to rely on the services of data scientists or the IT department
- The goal is to give BI tool users more freedom and responsibility at the same time
- This notion of user independence and self-sufficiency with company data leads to a decentralization of BI in the company
Therefore, it is not enough to provide the user with modern software with an associative data model in which he can filter at will and perhaps has some other freedoms, such as sorting columns or investigating detailed levels by drill-downs, and then speak of self-service. “Real” self-service begins where the user leaves the IT path and builds his own analysis path.
Lord of the data
Why is it becoming more and more necessary for the departments to get their own data access, to create their own analyses, to be able to integrate their own data?
In an (economic) world in which decisions have to be made faster and more often, employees need permanent and complete access to the data that forms the basis for decisions. If the relationships change or new constellations arise at short notice, the specialist departments must be able to act independently quickly in order to determine the right findings and derive the right decisions from them.
If you first have to take the detour via the IT department, where the implementation times in large companies often extend over several days or even weeks due to predefined processes or overloading of the IT department until changes can be made productive, the data is already obsolete and any competitive advantage lost.
Irrespective of data availability or time-to-market, the gain in knowledge plays a very important role: the departments know their data and have the necessary knowledge to interpret it – this is part of their daily work. IT can only ever implement what is described and assigned to them by the departments. A complete picture of the interrelationships is missing, but this is not one of the tasks of the IT department. If, however, the departments are able to link the data freely, add new/local data and build up their own analyses, a wide variety of new findings can result.
How do BI functions and knowledge gain relate to each other?
How can you give the specialists their own complete insight into the data?
In current BI models, you will find many functions that become more complex and thus more extensive depending on the requirements and the role of the user. From our point of view, self-service begins precisely when the user develops something new or changes something existing that did not exist before.
In order to clarify this connection, let us have a look at the following diagram:
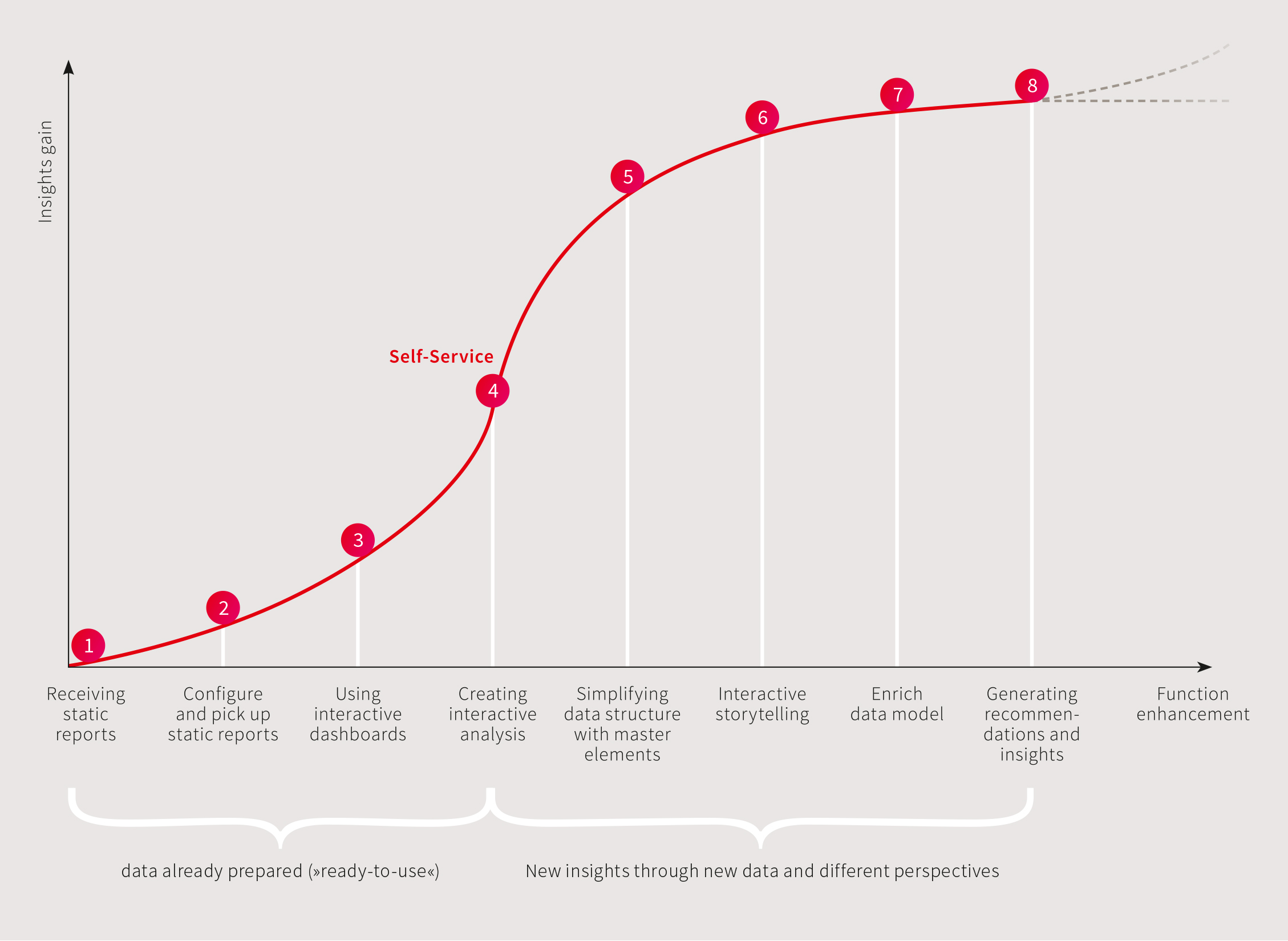
Figure: Increasing the acquisition of knowledge through increasing personal responsibility
The points (1) to (3) describe functions of classical, traditional BI, many of us know and use them every day:
I can be the recipient of a report that provides me with a particular metric (1). No more and no less – I am always informed about the current status of the key figure by e-mail.
Perhaps I have the right to configure such reports myself (2) – in other words, I can change the parameters or adjust the e-mail recipients. Increases the knowledge gain only slightly, because I can adjust the filters – so I can send the report instead of regions perhaps still by districts.
I also have access to an interactive dashboard (3) – where I can filter at will, view the data from different angles, sometimes from a time perspective, sometimes product-driven. I’ve already achieved a lot and can draw some conclusions – but when it comes to key figures and presentations, I’m dependent on the specifications and can’t let my own ideas flow in ad hoc.
From point (4) it becomes exciting – I have the possibility to create my own analysis elements in the form of graphs and tables, I can combine dimensions and facts in such a way that I can derive further insights from them – thus I am able to create new relationships that can afford benefits for my company and myself.
The points (5) to (8) provide me with even more comprehensive possibilities for analysis, ranging from the use of reusable master elements to importing my own local data (e.g. Excel) and editing the data model. I thus have full insight into my data and can enrich and process it as I like, make it available to others, distribute it, etc.
Last but not least
Surely, these activities require a lot not only of expertise but also of technical skills, and not every user will be able to perform every function.
It is therefore important to think about suitable role concepts.
In addition, it should not be underestimated how much effort the implementation of a self-service environment in the company entails for IT (even if it is to be relieved later):
- Selection of one or more suitable BI tools – these must be user-friendly and meet the requirements of the various roles that exist in the company
- Conception and structure of data governance – self-service only works if you can rely on the accuracy of the data
- A simple access to the data, as well as understandably structured basic data models must be a prerequisite
Once you did these prerequisites, your company can generate real benefit from Self-Service BI through faster implementation times in the specialist areas.
In the following blog posts, we will look at Self-Service BI in more detail and highlight the following aspects:
- Self-Service BI from the Business Perspective
- BI Functions in Detail
- Classification of Qlik Tools with Reference to Self-Service BI
Do you want/need more information? Our site can be found here
Or get in touch with us:
{{cta(’59acaef5-2729-46a2-9be9-52f39c573849′)}}
[1] Research and consulting institute BARC
[2] Manufacturer-independent community TDWI



0 Comments